graph TD;
style A fill:#91bcfd , stroke:#333, stroke-width:2px, rounded:true;
style B fill:#91bcfd , stroke:#333, stroke-width:2px, rounded:true;
style C fill:#91bcfd , stroke:#333, stroke-width:2px, rounded:true;
A[Research Question: Exposure and Health Outcome Relationship?] --> B[Preparation of Geospatial Exposure Data];
A --> C[Preparation of Health Outcome Data];
Geospatial exposure modeling methods and applications in human health
About Us: {SET}group

Eva Marques
Daniel Zilber
Ranadeep Daw
Mariana Alifa
Insang Song
Kyle Messier
Mitchell Manware (Not Pictured)
The Importance of Place


The Importance of Place

- Hurricane Matthew, 2016
- Hurricane Florence, 2018
- Swine Waste Concerns
- Fecal Bateria
- Nitrate and Phosphorous Pollution
- Infectious Diseases
The Importance of Place

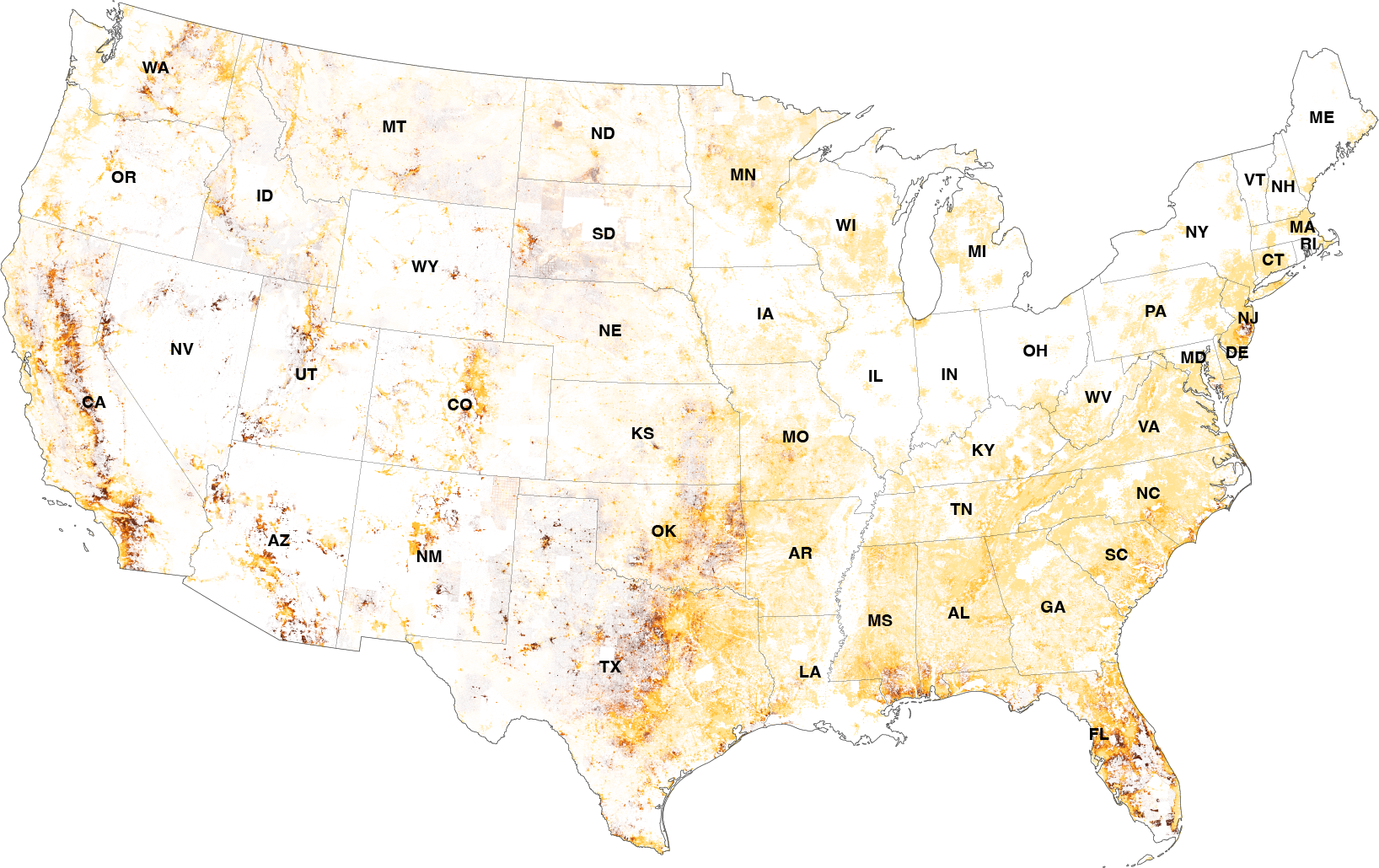



History of Spatial [Geo] Statistics Mining

Matheron and Krige developed geostatistical methods to predict ore content from core samples
Matheron coined the term “Kriging” after Krige
“Nugget” is a term used to random noise because predicting where gold nuggets were was so difficult
History of Spatial [Geo] Statistics: Forestry

Matérn developed correlation models for spatial variation for applications in Forestry
To this day, we use the “Matérn” covariance function
History of Spatial [Geo] Statistics: Petroleum Engineering

- Used to evaluate the oil and gas field reservoirs
- Uses geology and seismic data
History of Spatial [Geo] Statistics: Public Health

Cressie, 1990: Statistics for Spatial Data
Waller and Gotway, 2004: Applied Statistics for Public Health Data
Wide scale adoption for statisticians and engineers in ecological and human exposure and risk applications
Source and Receptor Geometries

Questions:
In figure C, what is an example of geospatial health data geometry at a point? Check all that apply.
In figure I, what is an example of geospatial health data geometry at an area? Check all that apply.
Geographically Weighted Regression
- \[ \bY(s) = X(s)\beta(s) + \varepsilon \]
- What is the key difference between LUR and GWR? Select one. Recall, LUR = \(\bY(s) = X(s)\beta + \varepsilon\)
- Hint: It’s in the \(\beta\)
![]()

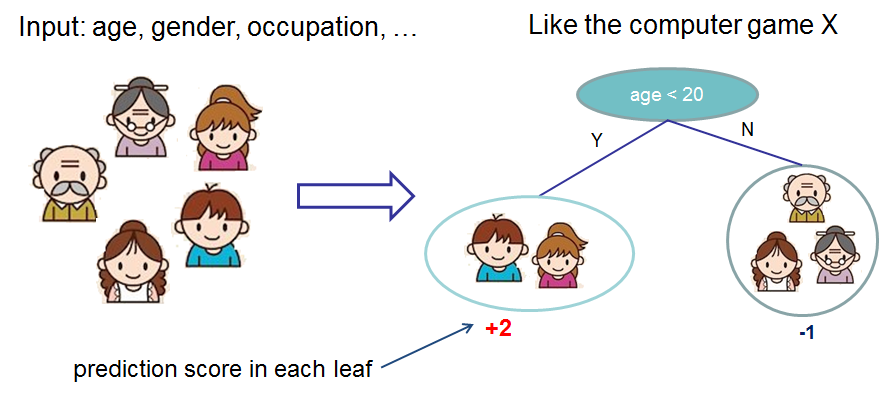
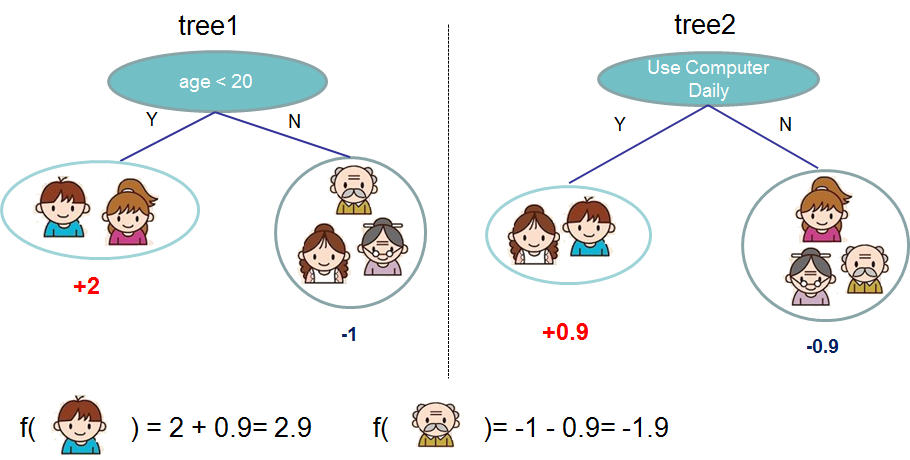
Machine Learning: Trees
Mechanistic
I would be remiss if I didn’t mention another entirely different class of exposure models
Mechanistic models are not statistical models
Mechanistic models are based on physics and chemistry
![]()

Hybrid
A consensus of multiple models is almost always better than any single model.
Requia, Weeberb J., et al. “An ensemble learning approach for estimating high spatiotemporal resolution of ground-level ozone in the contiguous United States.” Environmental science & technology 54.18 (2020): 11037-11047.
 Yu, Wenhua, et al. “Deep ensemble machine learning framework for the estimation of PM 2.5 concentrations.” Environmental Health Perspectives 130.3 (2022): 037004.
Yu, Wenhua, et al. “Deep ensemble machine learning framework for the estimation of PM 2.5 concentrations.” Environmental Health Perspectives 130.3 (2022): 037004.

Classical Framework for Geospatial Risk Assessment
