6 Linkage to Census Units




Linking Geocoded Addresses to Census Units and Social Determinants of Health Data in R
Date Modified: September 13, 2023
Author: Lara P. Clark ![]()
Key Terms: Data Integration, Social Determinants of Health, Geocoded Address, GeoID, Geographic Unit
Programming Language: R
6.1 Introduction
This tutorial provides example code in R:
To link geocoded addresses (i.e., geographic coordinates) to the specific US Census geographic units (e.g., tract) in which they are located.
To link data from the Agency for Healthcare Research and Quality (AHRQ) Social Determinants of Health Database (17) to those geocoded addresses.
6.1.1 Motivation
Linking geocoded addresses to US Census geographic units is a common step in environmental health data integration workflows. First, using geographic information systems (GIS) software, the geocoded addresses are mapped to the specific Census geographic units (e.g., Census tracts) in which they are located. Second, the Census geographic unit identifying code (or, geoID) is matched to each geocoded address. The result is a table of geocoded addresses and their corresponding Census geoIDs.
The Census geoIDs can then serve as the basis for linking additional data to each geocoded address. Many types of data with importance for environmental health applications are available by Census geoID. Specifically, the Census collects and provides data by Census geoID for various social determinants of health (SDOH). Such Census SDOH data describe poverty, race/ethnicity, language, housing, and other socioeconomic characteristics. Increasingly, other data providers (e.g., other government agencies, research institutions, community science groups) are making their data available by Census geoID to help facilitate linkages with SDOH data. Such data cover various environment, disaster-related, health, and built environment characteristics.
The following table lists example environmental health data sources readily available by Census geoID from US federal agencies.
| Data source | Geographic units | Example topics |
|---|---|---|
| AHRQ Social Determinants of Health Database | County, ZIP code, tract | Demographic characteristics, housing and transportation characteristics, food access, healthcare characteristics |
| CDC National Environmental Public Health Tracking Network | State, county | Heat, sunlight and ultraviolet exposure, built environment characteristics, asthma, heat-related illnesses |
6.1.2 Background
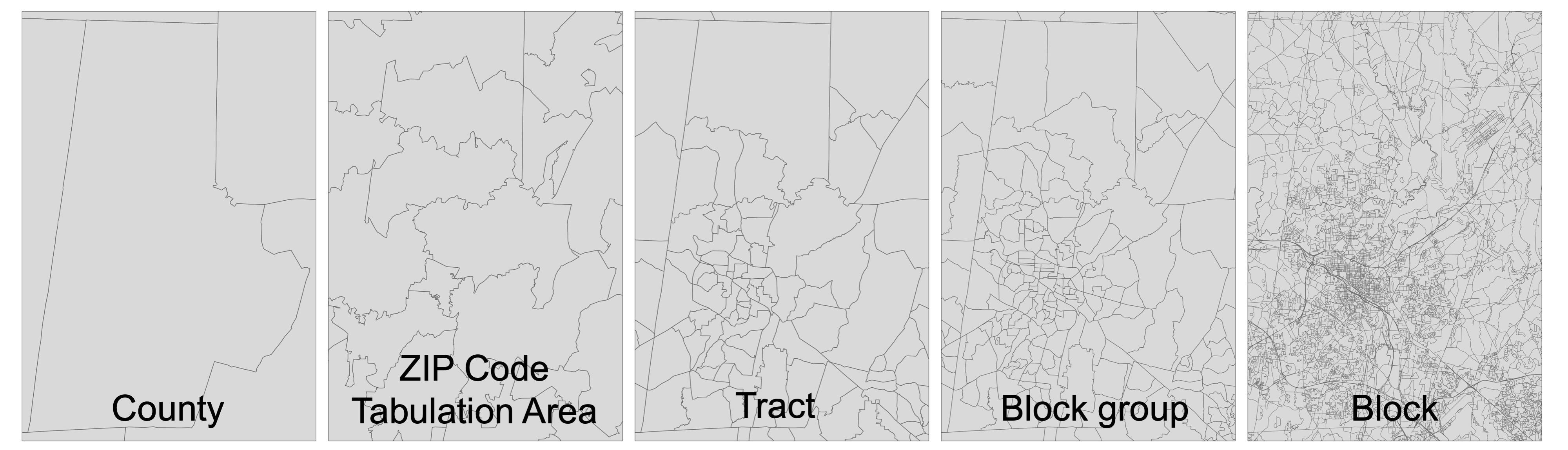
The Census defines geographic boundaries at various spatial scales. Common examples in environmental health workflows include (from coarsest to finest spatial scale): states, counties, tracts, block groups, and blocks. These boundaries are completely non-overlapping, such that block boundaries are nested within block groups, which are nested within tracts, which are nested within counties, which are nested within states.
The Census defines the boundaries of tracts and block groups to scale with local population: that is, in areas with higher population density (e.g., urban cores), these geographic units have finer spatial scale (i.e., smaller land area per unit) and in areas with lower population density (e.g., rural areas), the geographic units have coarser spatial scale (i.e., larger land area per unit). As a result, the spatial scale of geographic units varies substantially across the US. The shape of geographic units also varies substantially: the Census defines these boundaries to follow political boundaries (e.g., state boundaries) as well as physical features (e.g., roads, rivers), which often have irregular shapes.
The variable shape and spatial scale of Census geographic units is in contrast with spatial grids– in which each geographic unit (i.e., grid cell) has the same shape and spatial resolution. Such spatial grids are common for environmental data.
ZIP Code Tabulation Areas (ZCTAs), which represent the geographic areas used by the US Postal Service for ZIP codes, are another common boundary used in environmental health workflows. ZCTAs have no spatial relationship with block groups, tracts, counties, or states: that is, ZCTAs can cross or overlap those other geographic boundaries. Like other Census geographic boundaries, ZCTAs vary in spatial resolution and shape across the US. The spatial scale of ZCTAs is, on average, finer than counties but coarser than tracts.
The following figure illustrates the variable spatial scale and shape of each type of geographic boundary:
The Census assigns a unique identifying code, or geoID, to each geographic unit. This Census geoID is also referred to as a FIPS (Federal Information Processing Series) code.
The following table describes common types of Census geographic units and the structure of their geoIDs.
| Geographic Unit | Total Units1 | GeoID Description and Structure | Example Unit GeoID | Example Unit Name |
|---|---|---|---|---|
| State | 50 | 2-digit state (S) code = SS | 09 | Connecticut (CT) |
| County | 3143 | 5-digit code = 2-digit state (S) code + 3-digit county (C) code = SSCCC | 09007 | Middlesex County, CT |
| Zip Code Tabulation Area (ZCTA) | 33,642 | 5-digit ZCTA (Z) code = ZZZZZ | 06480 | ZCTA for Portland, CT |
| Tract | 84,414 | 11-digit code = 2-digit state (S) code + 3 digit county (C) code + 6-digit tract (T) code = SSCCCTTTTTT | 09007560100 | Tract 560100 in Middlesex County, CT |
| Block group | 239,780 | 12-digit code = 2-digit state (S) code + 3 digit county (C) code + 6-digit tract (T) code + 1-digit block group (G) code = SSCCCTTTTTTG | 090075601001 | Block group 1 in Tract 560100 in Middlesex County, CT |
| Block | 8,132,968 | 15-digit code = 2-digit state (S) code + 3 digit county (C) code + 6-digit tract (T) code + 4-digit block (B) code (which contains the block group code as its first digit) = SSCCCTTTTTTBBBB | 090075601001004 | Block 1004 in Tract 560100 in Middlesex County, CT |
For states, counties, tracts, block groups, and blocks: the geoIDs for the finer spatial scale units are constructed from the geoIDs for the coarser spatial scale units in which they are located. This makes it possible to extract, for example, the tract geoID from the block geoID based on digit number.
6.1.3 Considerations
The following are important considerations for linking geocoded addresses to Census geographic boundaries for environmental health applications.
Temporal Considerations: The Census periodically updates its geographic boundaries, such as tracts, block groups, and blocks. For example, the Census may add, remove, or modify specific geographic units (and associated geoIDs) as the population changes over time. Thus, it is important to select the correct years (or, vintages) of Census geographic boundaries needed for linking each data source of interest. For example, linking SDOH data provided for year-2010 vintage Census tract boundaries would require the year-2010 vintage of Census tract geoIDs for each geocoded address.
Spatial Scale Considerations: The spatial scale of tracts, block groups, and blocks varies substantially across the US, with finer spatial scale in urban areas and coarser scale in rural areas. Thus, it is important to select the Census geographic boundary with appropriate spatial resolution for the specific environmental health application.
Privacy Considerations: Various web-based geocoding tools support look-up of Census geoIDs by street addresses or geographic coordinates. However, such web-based tools require sending geolocation information over the internet, which can risk exposing private geolocation information. To meet data protection guidelines for environmental health applications, this tutorial instead uses a fully offline approach for handling geolocation information.
6.2 Tutorial
6.2.1 Install R Packages
This tutorial uses the R packages sf (1,8), tidyverse (18), tigris (19), and tmap (20). The following code installs and loads these packages:
6.2.2 Prepare Geocoded Addresses
The first step is to prepare the geocoded addresses (i.e., geographic coordinates or latitude/longitude) for mapping in R.
For this tutorial, we will use sample public data to represent geocoded addresses of, for example, participants in a health cohort study. This sample public data will be the coordinates for the city halls of the five largest cities in North Carolina. These coordinates were identified by searching Google Maps. The following code reads these coordinates into a table in R with columns for id, latitude, and longitude:
# create a table of sample public geocoded addresses
geo_addresses_tbl <- tibble(
id = c(
"01-charlotte",
"02-raleigh",
"03-greensboro",
"04-durham",
"05-winston-salem"
),
latitude = c(
35.21599030178876,
35.78019493350421,
36.07391214865624,
35.99607916214782,
36.09512361249636
),
longitude = c(
-80.80170873958926,
-78.64278743612566,
-79.7883534467845,
-78.89907326845271,
-80.24283630316438
)
)
# view the table
print(geo_addresses_tbl)## # A tibble: 5 × 3
## id latitude longitude
## <chr> <dbl> <dbl>
## 1 01-charlotte 35.2 -80.8
## 2 02-raleigh 35.8 -78.6
## 3 03-greensboro 36.1 -79.8
## 4 04-durham 36.0 -78.9
## 5 05-winston-salem 36.1 -80.2Next, we’ll transform this table to an explicitly spatial data type: simple features (sf). This will allow us to use the point locations for spatial analysis using the sf package in R.
To do this, we will need to specify the coordinate reference system (CRS) used for the city hall coordinates. For this example, we retrieved the city hall coordinates from Google Maps, which uses the World Geodetic System 1984 (WGS84) CRS.
If you need to find the coordinate reference system information for your geolocation data, here are a few places to look:
Metadata for geolocation data
Documentation for geocoding method (e.g., geocoding software) or geolocation data collection method (e.g., GPS device)
General documentation for data provider
There are multiple formats available in R for specifying the CRS: proj4, well known text (wkt), and European Petroleum Survey Group (EPSG) format (21). Here, we will specify the WGS84 CRS using the EPSG format, which is a 4-digit numeric identifying code. We can look up the EPSG code for WGS84 by searching a spatial reference catalog. There, we find that the EPSG code is4326.
The following code transforms the table of city hall locations to a simple features object:
# transform table to simple features
geo_addresses_sf <- sf::st_as_sf(geo_addresses_tbl,
coords = c("longitude", "latitude"),
crs = "EPSG:4326"
)
# view simple features
print(geo_addresses_sf)## Simple feature collection with 5 features and 1 field
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: -80.80171 ymin: 35.21599 xmax: -78.64279 ymax: 36.09512
## Geodetic CRS: WGS 84
## # A tibble: 5 × 2
## id geometry
## * <chr> <POINT [°]>
## 1 01-charlotte (-80.80171 35.21599)
## 2 02-raleigh (-78.64279 35.78019)
## 3 03-greensboro (-79.78835 36.07391)
## 4 04-durham (-78.89907 35.99608)
## 5 05-winston-salem (-80.24284 36.09512)Now, we can see that each city hall has associated geometry in point format. We can also confirm that the correct CRS (WGS84) is now associated with the city hall locations.
6.2.3 Access Census Geographic Boundaries
The second step is to prepare the Census geographic boundaries for mapping in R. For this tutorial, we’ll use the tigris package to load the Census tract boundaries for North Carolina in year-2010 (i.e., year-2010 vintage). Using an R package like tigris to load the Census geographic boundaries will help keep the workflow reproducible by documenting all of the steps in R. The following code reads the North Carolina 2010 Census tract boundaries into R as simple features:
# download Census tracts in North Carolina in 2010 as simple features
nc_tracts_2010_sf <- tigris::tracts(state = "NC", year = 2010)
# view the first several rows of the Census tracts simple features
head(nc_tracts_2010_sf)Each tract has associated geometry in polygon format plus 14 additional attributes (i.e., variables, columns). Importantly, the Census tract geoID (i.e., 11-digit identifying code) for year-2010 is stored in the column GEOID10.
We can see that the CRS listed above for the Census tract boundaries (NAD83) is different from the CRS for the city hall locations (WGS84). This will be important for the linkage step.
Next, we can view the geometry of the tracts by creating a map:
# create a map of the Census tracts
nc_tracts_2010_map <- tmap::tm_shape(nc_tracts_2010_sf) +
tmap::tm_polygons(lwd = 0.5)
# view the map
print(nc_tracts_2010_map)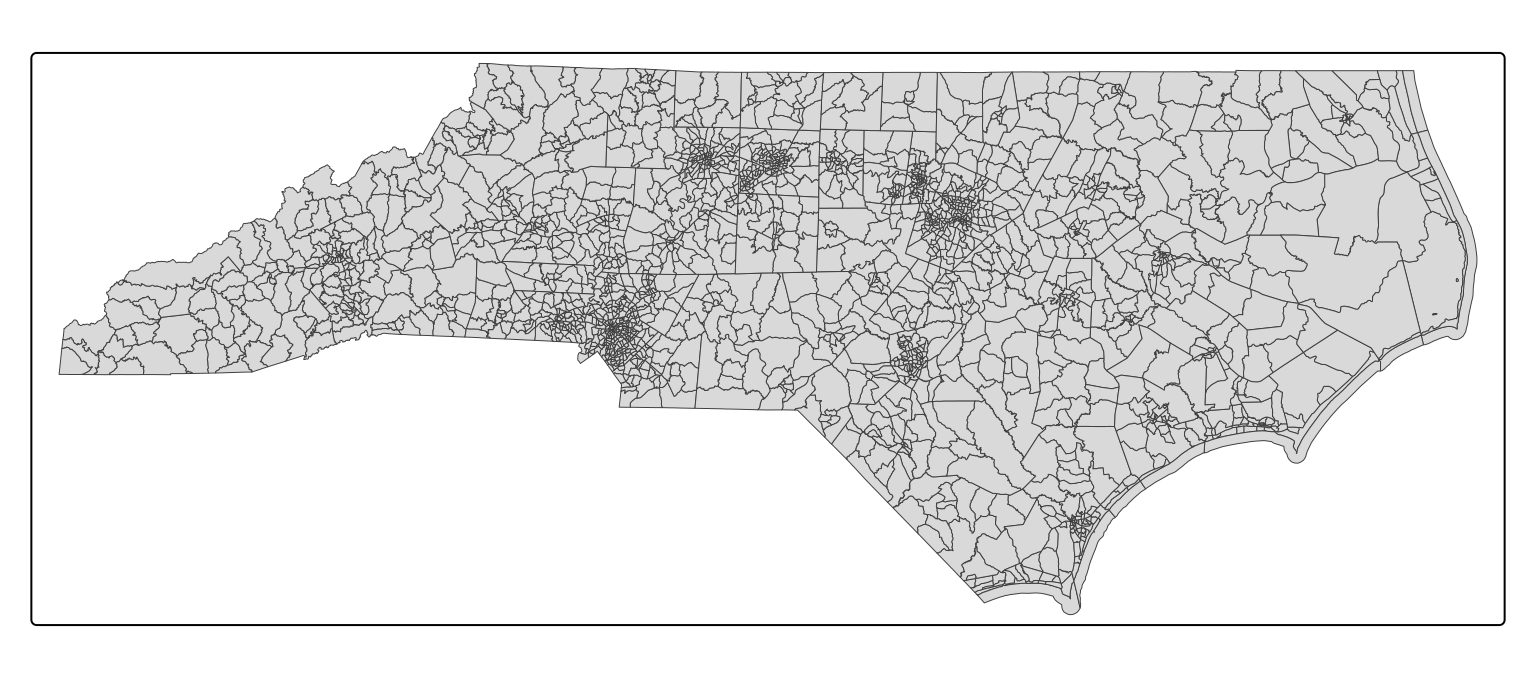
Other types and vintages of Census geographic boundaries are available through tigris and the related tidycensus package (22). In most cases, these boundaries are available for recent years (i.e., 1990 to present) and are accessed by state (i.e., users can download geographic boundaries for one state at a time, in separate files).
Census geographic boundaries are also available to download by state for years 2007 to present via the Census TIGER/Lines website (23).
Historic Census geographic boundaries (i.e., 1910 to present) are available through IPUMS NHGIS (24). Additionally, IPUMS NHGIS provides many boundaries at the national scale (i.e., such that users can download geographic boundaries for the entire US in a single file). Here is an example workflow for accessing historic Census geographic boundaries via IPUMS NHGIS in R (25).
6.2.4 Link Geocoded Addresses to Census Geographic Boundaries
The third step is to link each geocoded addresses to the geoID of the Census geographic unit that contains it. To do this, we’ll first need to prepare the geocoded addresses and Census geographic boundaries in the same CRS. The following code transforms the CRS of the geocoded addresses to match the the CRS of the Census geographic boundaries (NAD83) and then maps them together:
# transform city hall locations to match CRS of Census tracts
geo_addresses_crs_sf <- sf::st_transform(geo_addresses_sf,
crs = sf::st_crs(nc_tracts_2010_sf)
)
# create a map of the Census tracts with the city hall locations
linkage_map <- tmap::tm_shape(nc_tracts_2010_sf) +
tmap::tm_polygons(lwd = 0.5) +
tmap::tm_shape(geo_addresses_crs_sf) +
tmap::tm_dots(
col = "red",
size = 0.25
)
# view the map
print(linkage_map)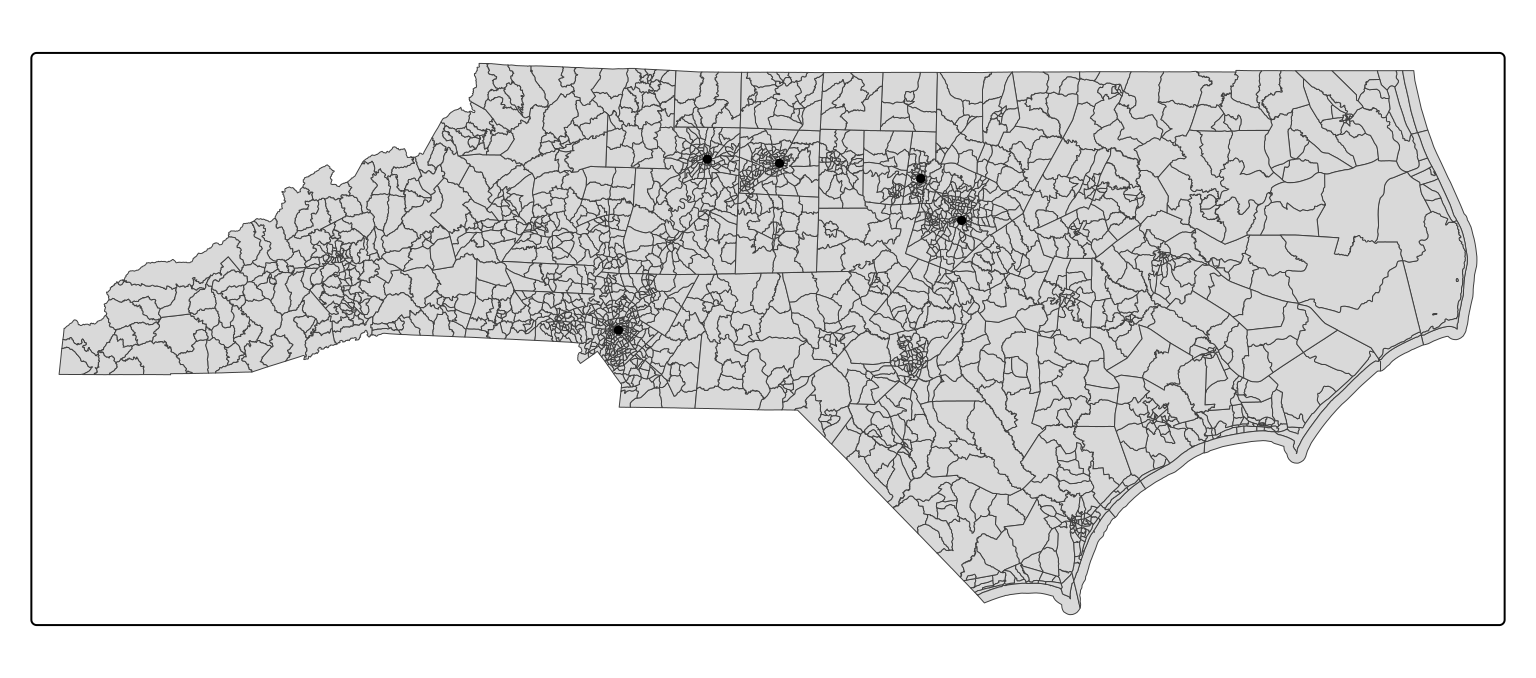
Now that the geocoded addresses and Census tracts are in the same CRS, we can link each geocoded address to the Census tract that contains it using a spatial join. The following code produces a table of geocoded addresses linked to Census tract geoIDs:
# link geocoded addresses to the Census tracts that contain them
geo_addresses_linkage_sf <- sf::st_join(geo_addresses_crs_sf,
nc_tracts_2010_sf,
left = TRUE)
# create linked table with geocoded addresses id paired with Census tract geoID
geo_addresses_linkage_tbl <- sf::st_drop_geometry(geo_addresses_linkage_sf) %>%
dplyr::rename(geoid_tract_2010 = GEOID10) %>%
dplyr::select(id, geoid_tract_2010)
# view the linked table
print(geo_addresses_linkage_tbl)## # A tibble: 5 × 2
## id geoid_tract_2010
## <chr> <chr>
## 1 01-charlotte 37119001100
## 2 02-raleigh 37183050100
## 3 03-greensboro 37081010800
## 4 04-durham 37063002200
## 5 05-winston-salem 370670001006.2.5 Link AHRQ SDOH Data to Geocoded Addresses
The fourth step is to link the AHRQ SDOH data to each geocoded address based on the Census geoID.
To start, we’ll need to prepare the AHRQ SDOH data for Census tracts. This data is available to download as an Excel (XLSX) spreadsheet on the AHRQ SDOH website as shown in this screenshot:
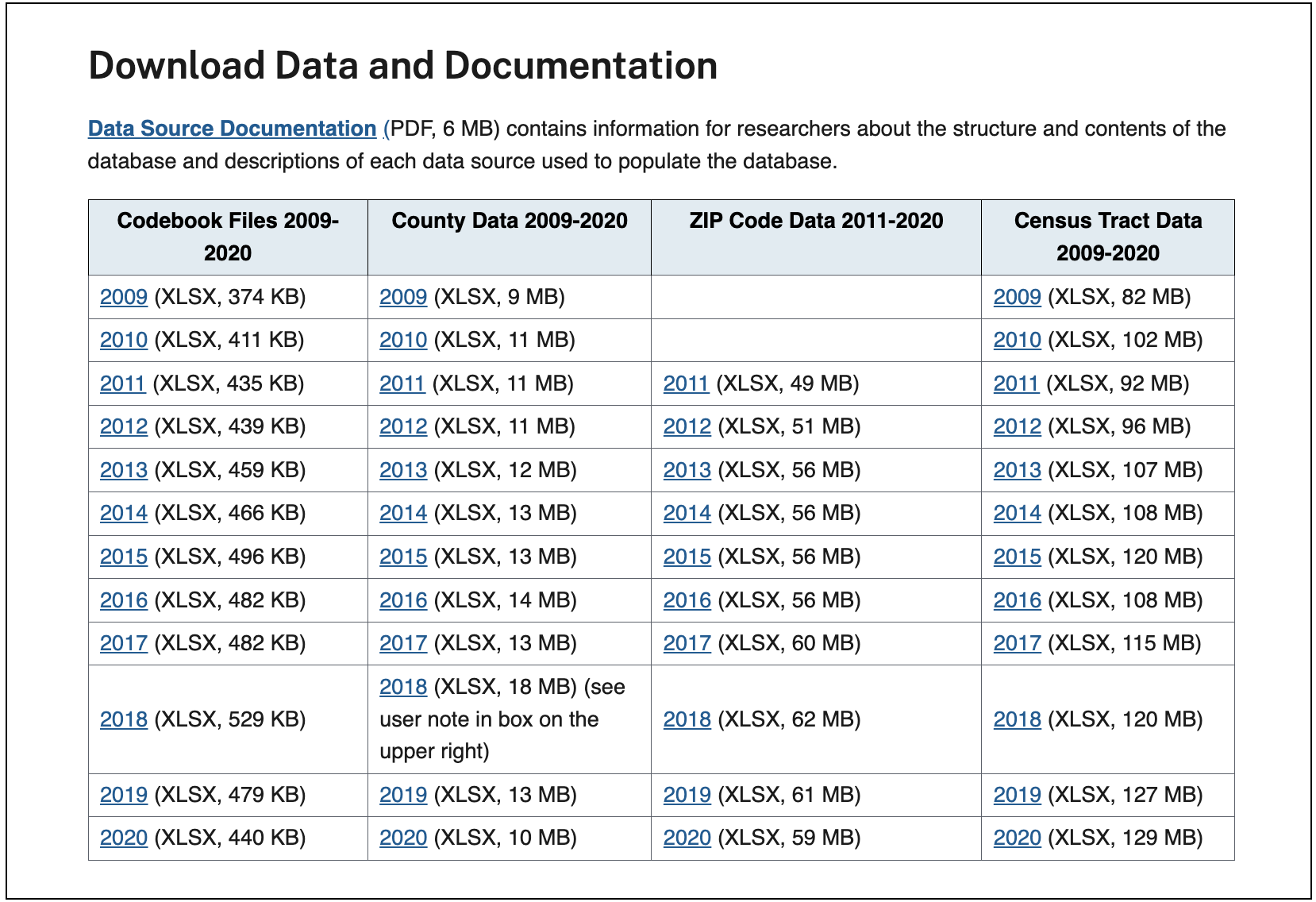
Before linking, we’ll need to check the vintage of Census tracts used in the AHRQ SDOH data. To do this, we can review the AHRQ SDOH Data Source Documentation (accessed through the link shown in the website screenshot above). There we find the following information:
The SDOH Database 2009 file has census tracts based on the 2000 census tract boundaries. The SDOH Database for 2010-2019 SDOH files uses 2010 census tract boundaries, and the 2020 file uses 2020 census tract boundaries.
Based on this information, we can use the geoIDs for year-2010 vintage Census tracts we prepared for the geocoded addresses in the previous step to link the AHRQ SDOH data for years 2010-2019. If we would instead prefer to link the AHRQ SDOH data for year 2009 or 2020, we would first need to repeat the previous steps to link the geoIDs for year-2000 vintage or year-2020 vintage Census tracts, respectively, to the geocoded addresses.
For this example, we will link the AHRQ SDOH data for Census tracts in 2010 to our sample geocoded addresses on the basis of the year-2010 Census tract geoID. The SDOH AHRQ data for Census tracts in 2010 is provided as an Excel file. Because Excel files can contain multiple sheets, we’ll need to first download and open the Excel file to understand which sheet(s) to read into R:
We find that the Excel file has two sheets: Layout and Data. The Layout sheet contains the data dictionary. The Data sheet contains >300 columns of SDOH data by geoID for the >70,000 Census tracts in the US in 2010.
The following code downloads the Excel file and reads its Data sheet into a table in R:
# download Excel file using the URL provided in the screenshot above
sdoh_tracts_2010_url <-
"https://www.ahrq.gov/downloads/sdoh/sdoh_2010_tract_1_0.xlsx"
# specify your file path for downloading the Excel file
sdoh_tracts_2010_xlsx <-
"/ YOUR FILE PATH /sdoh_2010_tract_1_0.xlsx"
# read the "Data" sheet of the Excel file into a table R
# note that you may need to provide a complete file path for the Excel file
sdoh_tracts_2010_tbl <- readxl::read_xlsx(sdoh_tracts_2010_xlsx,
sheet = "Data")## # A tibble: 6 × 355
## YEAR TRACTFIPS COUNTYFIPS STATEFIPS STATE COUNTY REGION TERRITORY
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 2010 01001020100 01001 01 Alabama Autauga County South 0
## 2 2010 01001020200 01001 01 Alabama Autauga County South 0
## 3 2010 01001020300 01001 01 Alabama Autauga County South 0
## 4 2010 01001020400 01001 01 Alabama Autauga County South 0
## 5 2010 01001020500 01001 01 Alabama Autauga County South 0
## 6 2010 01001020600 01001 01 Alabama Autauga County South 0
## # ℹ 347 more variables: ACS_TOT_POP_WT <dbl>, ACS_TOT_POP_US_ABOVE1 <dbl>,
## # ACS_TOT_POP_ABOVE5 <dbl>, ACS_TOT_POP_ABOVE15 <dbl>,
## # ACS_TOT_POP_ABOVE16 <dbl>, ACS_TOT_POP_16_19 <dbl>,
## # ACS_TOT_POP_ABOVE25 <dbl>, ACS_TOT_CIVIL_POP_ABOVE18 <dbl>,
## # ACS_TOT_CIVIL_VET_POP_ABOVE25 <dbl>, ACS_TOT_OWN_CHILD_BELOW17 <dbl>,
## # ACS_TOT_CIVILIAN_LABOR <dbl>, ACS_TOT_CIVIL_EMPLOY_POP <dbl>,
## # ACS_TOT_WORKER_HH <dbl>, ACS_TOT_WORKER_NWFH <dbl>, …We can see that the variable TRACTFIPS contains the 11-digit geoID for Census tracts in character format, which matches the geoID format we prepared in the previous step .
For linkages based on geoID, it is important to check that the geoID is in the same format across data sources. We recommend using character format (rather than numeric format) for Census geoIDs. This will preserve padded zeroes in geoIDs (e.g., state geoID for Alabama is 01 rather than 1) such that each type of geoID has the expected number of digits (e.g., 2-digits for state geoID).
For this example, we can choose to link the following sample of SDOH variables identified by exploring the Layout sheet:
ACS_PCT_INC50: Percentage of population with income to poverty ratio under 0.50POS_DIST_ED_TRACT: Distance in miles to the nearest emergency department, calculated using population weighted tract centroidsACS_PCT_HU_NO_VEH: Percentage of housing units with no vehicle available
The following code joins those SDOH data variables to the geocoded addresses based on the Census tract geoID:
# rename geoID in SDOH table to match the geoID in the geocoded addresses table
# select the SDOH variables of interest
sdoh_tracts_2010_tbl <- sdoh_tracts_2010_tbl %>%
dplyr::rename(geoid_tract_2010 = TRACTFIPS) %>%
dplyr::select(geoid_tract_2010,
ACS_PCT_INC50,
POS_DIST_ED_TRACT,
ACS_PCT_HU_NO_VEH)
# join the SDOH table to the geocoded addresses based on geoID
geo_addresses_sdoh_tbl <- dplyr::left_join(geo_addresses_linkage_tbl,
sdoh_tracts_2010_tbl,
by = "geoid_tract_2010")
# view the resulting linked table
print(geo_addresses_sdoh_tbl)## # A tibble: 5 × 5
## id geoid_tract_2010 ACS_PCT_INC50 POS_DIST_ED_TRACT ACS_PCT_HU_NO_VEH
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 01-charlot… 37119001100 3.68 0.85 7.24
## 2 02-raleigh 37183050100 6.77 2.8 25.5
## 3 03-greensb… 37081010800 6.16 0.99 16.4
## 4 04-durham 37063002200 25.9 2.62 7.63
## 5 05-winston… 37067000100 9.01 3.35 16.5Now, we have a linked table of geocoded addresses (by individual id) linked to the SDOH data. We can also save the linked table as a CSV file using the following code:
6.3 Concluding Remarks
This tutorial demonstrates how to link geocoded addresses for individuals to Census geographic boundaries and then to SDOH data available for those Census geographic boundaries. Additional tabular data available for Census geographic boundaries can then be readily linked to further develop an integrated dataset for individuals. Such integrated datasets can be used to investigate relationships between SDOH and health outcomes for individuals.
References
Total number of geographic units in the US in 2020 (Source: Census Bureau)↩︎